Projects
Research and academic projects listed in reverse chronological order. I'm currently transitioning my focus from applied engineering to applied research. Stay tuned for updates!
2025
-
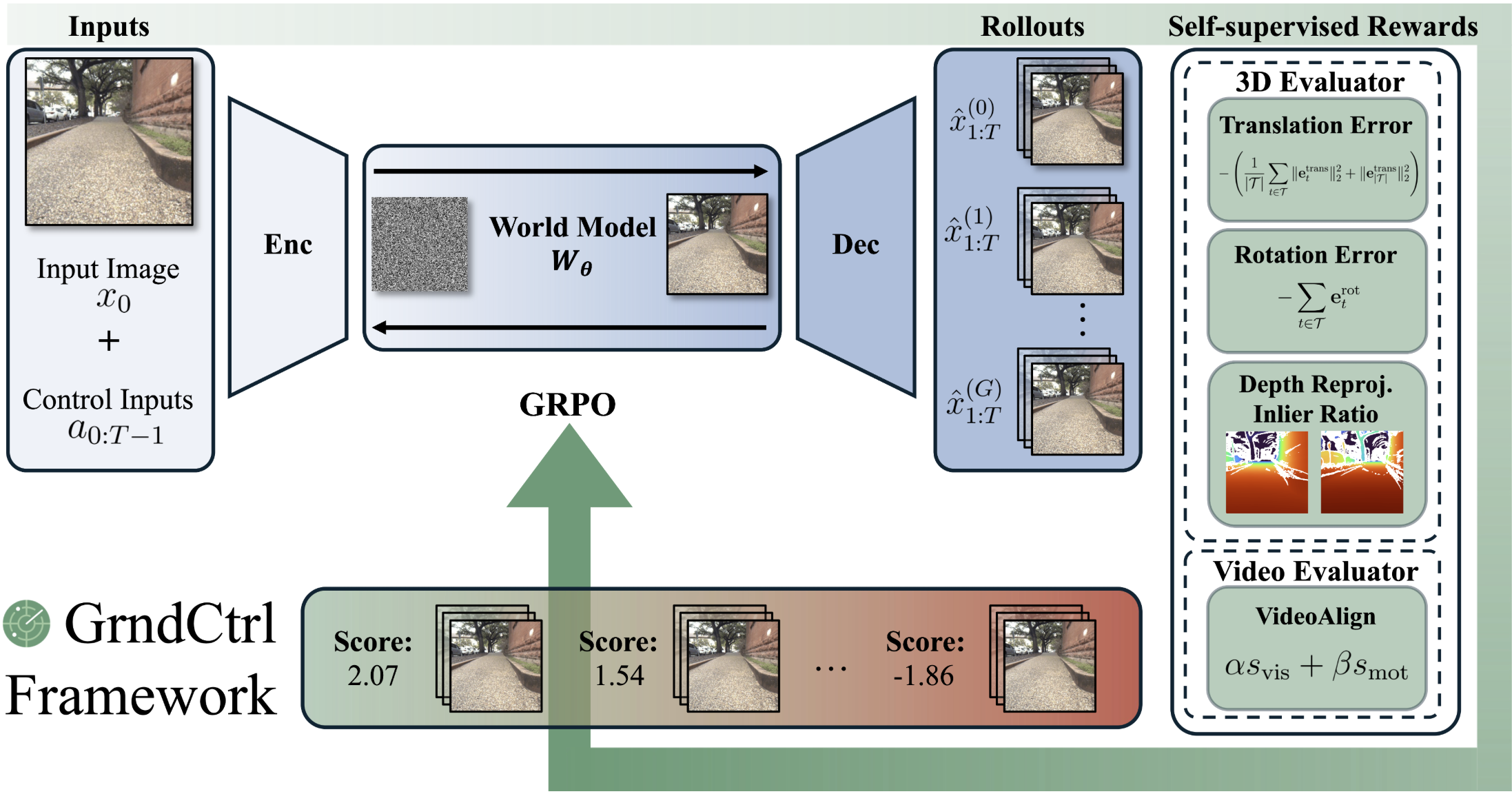 GrndCtrl: Grounding World Models via Self-Supervised Reward AlignmentHaoyang He, Jay Patrikar, Dong-Ki Kim, Max Smith, Daniel McGann, Ali-akbar Agha-mohammadi, Shayegan Omidshafiei, and Sebastian SchererAccepted to World Modeling Workshop 2026 & Submitted to [REDACTED]
GrndCtrl: Grounding World Models via Self-Supervised Reward AlignmentHaoyang He, Jay Patrikar, Dong-Ki Kim, Max Smith, Daniel McGann, Ali-akbar Agha-mohammadi, Shayegan Omidshafiei, and Sebastian SchererAccepted to World Modeling Workshop 2026 & Submitted to [REDACTED]Recent advances in video world modeling have enabled large-scale generative models to simulate embodied environments with high visual fidelity, providing strong priors for prediction, planning, and control. Yet, despite their realism, these models often lack geometric grounding, limiting their use in navigation tasks that require spatial coherence and long-horizon stability. We introduce Reinforcement Learning with World Grounding (RLWG), a self-supervised post-training framework that aligns pretrained world models with a physically verifiable structure through geometric and perceptual rewards. Analogous to reinforcement learning from verifiable feedback (RLVR) in language models, RLWG can use multiple rewards that measure pose cycle-consistency, depth reprojection, and temporal coherence. We instantiate this framework with GrndCtrl, a reward-aligned adaptation method based on Group Relative Policy Optimization (GRPO), yielding world models that maintain stable trajectories, consistent geometry, and reliable rollouts for embodied navigation. Like post-training alignment in large language models, GrndCtrl leverages verifiable rewards to bridge generative pretraining and grounded behavior, achieving superior spatial coherence and navigation stability over supervised fine-tuning in outdoor environments.
-
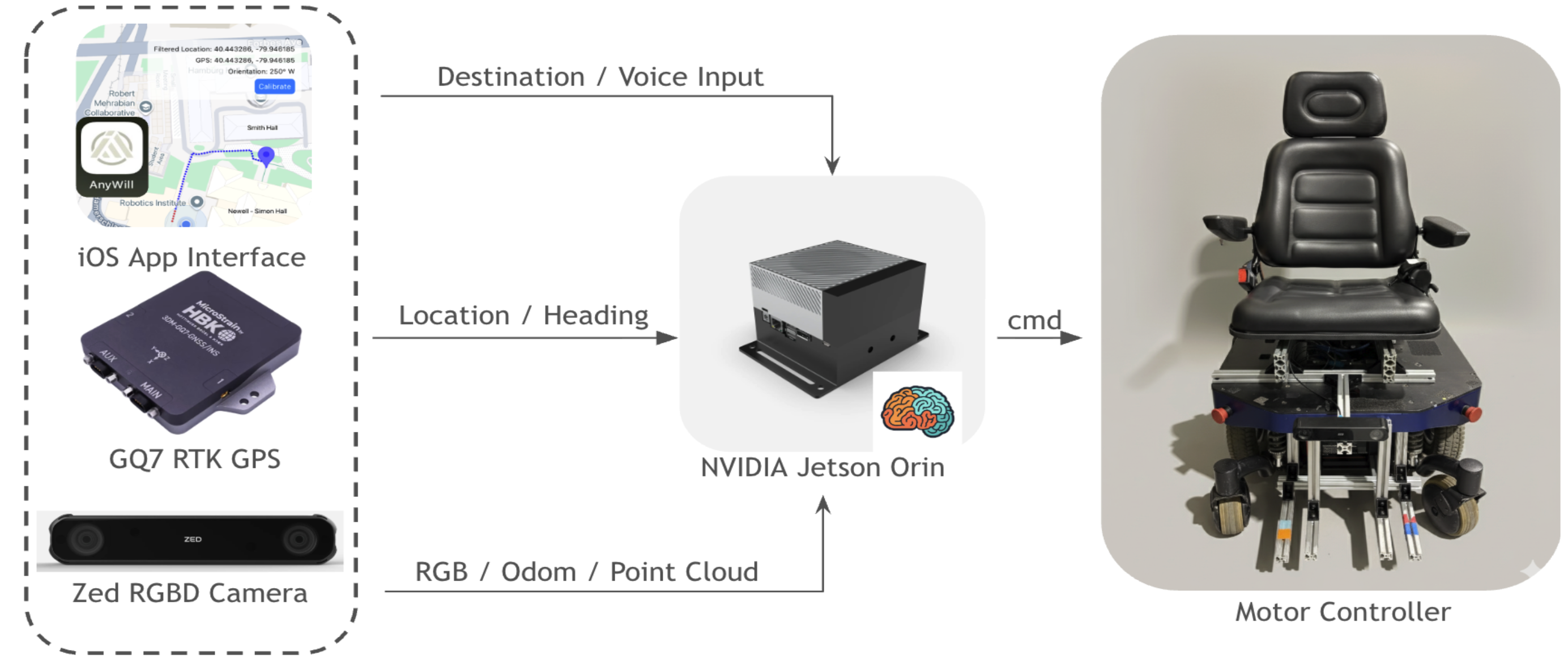 AnyWill: A Human-Interactive Autonomous Wheelchair for Outdoor Urban NavigationHaoyang He, Yu-Hsin Chan, Chiawen Liao, Chao-I Tuan, and Sonic KuoMRSD Capstone Project 2025
AnyWill: A Human-Interactive Autonomous Wheelchair for Outdoor Urban NavigationHaoyang He, Yu-Hsin Chan, Chiawen Liao, Chao-I Tuan, and Sonic KuoMRSD Capstone Project 2025Uneven, cluttered sidewalks and constant steering impose significant physical and cognitive load on wheelchair users. This report presents AnyWill, an outdoor, user-interactive autonomous wheelchair designed to provide end-to-end mobility on urban sidewalks while respecting individual preferences. The system retrofits a commercial powered wheelchair with a ZED-X RGB-D camera, dual-antenna RTK GNSS/IMU, and a Jetson AGX Orin running ROS 2. Visual and geometric features from first-person images and point clouds are fused into a learned bird’s-eye-view costmap using an inverse reinforcement learning model trained on expert teleoperation, capturing subtle terrain semantics such as curbs, rough pavement, and compliant surfaces. On top of this costmap, a global planner uses an OpenStreetMap-based wheelchair-accessible map, and a model predictive path integral local planner replans at 2 Hz to generate safe, comfortable trajectories. A companion iOS app allows users to set destinations, monitor progress, and optionally invoke a vision-language model planner that proposes semantically rich routes from first-person imagery for user approval. Safety is enforced through multiple hardware E-STOPs, a dedicated safety circuit, and conservative speed limits. In a 450 m Fall Validation Demonstration on real sidewalks, AnyWill successfully completed the route with a 1.2 m final error, avoided all static and dynamic pedestrians, and required only a single brief teleoperation during GNSS degradation, demonstrating the technical feasibility of user-interactive autonomous sidewalk mobility.
-
 RayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and ExplorationOmar Alama, Avigyan Bhattacharya, Haoyang He, Seungchan Kim, Yuheng Qiu, Wenshan Wang, Cherie Ho, Nikhil Keetha, and Sebastian SchererIROS 2025
RayFronts: Open-Set Semantic Ray Frontiers for Online Scene Understanding and ExplorationOmar Alama, Avigyan Bhattacharya, Haoyang He, Seungchan Kim, Yuheng Qiu, Wenshan Wang, Cherie Ho, Nikhil Keetha, and Sebastian SchererIROS 2025Open-set semantic mapping is crucial for open-world robots. Current mapping approaches either are limited by the depth range or only map beyond-range entities in constrained settings, where overall they fail to combine within-range and beyond-range observations. Furthermore, these methods make a trade-off between fine-grained semantics and efficiency. We introduce RayFronts, a unified representation that enables both dense and beyond-range efficient semantic mapping. RayFronts encodes task-agnostic open-set semantics to both in-range voxels and beyond-range rays encoded at map boundaries, empowering the robot to reduce search volumes significantly and make informed decisions both within & beyond sensory range, while running at 8.84 Hz on an Orin AGX. Benchmarking the within-range semantics shows that RayFronts’s fine-grained image encoding provides 1.34x zero-shot 3D semantic segmentation performance while improving throughput by 16.5x. Traditionally, online mapping performance is entangled with other system components, complicating evaluation. We propose a planner-agnostic evaluation framework that captures the utility for online beyond-range search and exploration, and show RayFronts reduces search volume 2.2x more efficiently than the closest online baselines.
2024
-
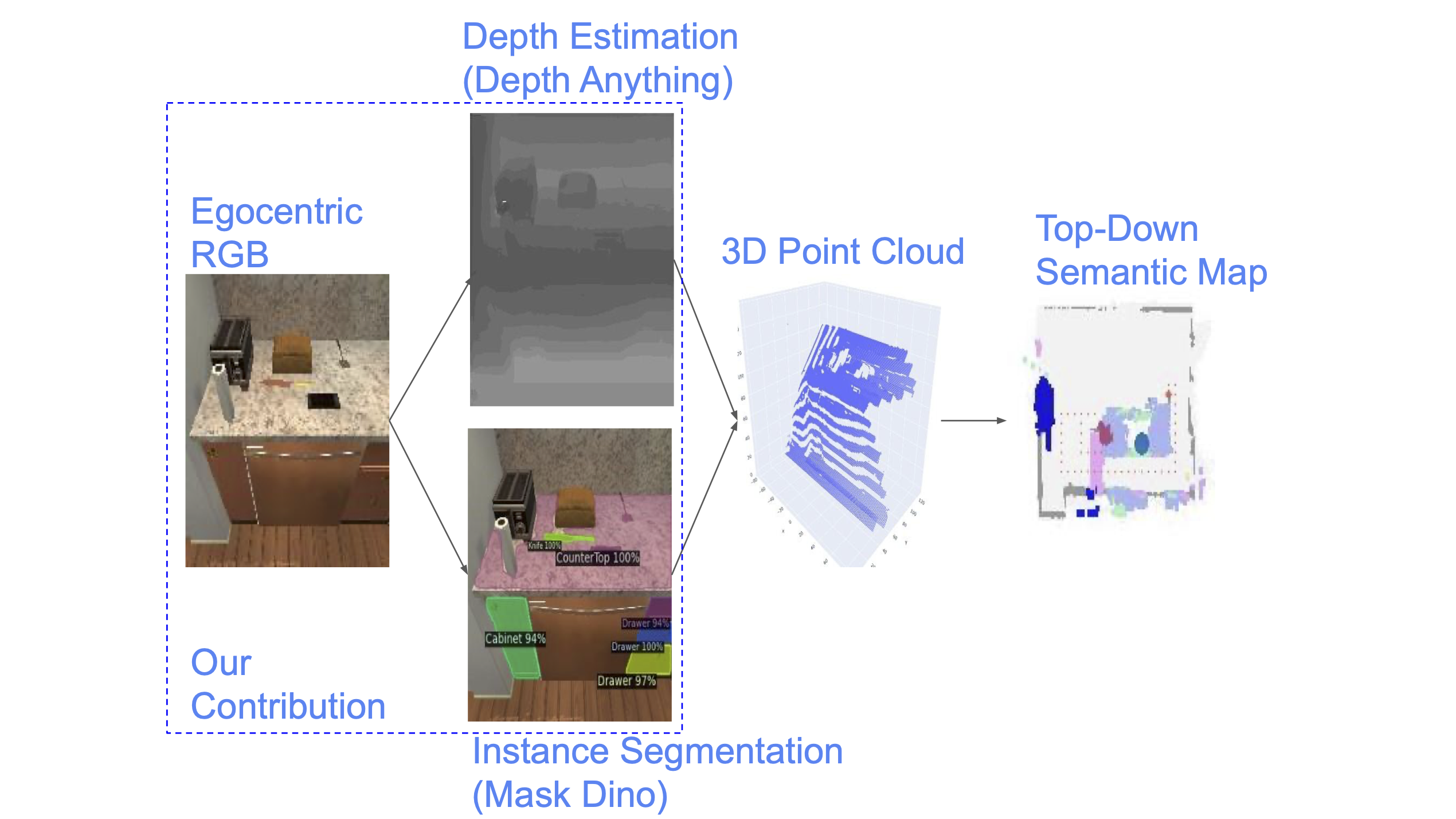 Multimodal Analysis of Embodied Instruction Following on ALFREDJustin Dannemiller*, Haoyang He*, Conner Pulling*, Eduardo Trevino*, and Renos Zabounidis*May 2024
Multimodal Analysis of Embodied Instruction Following on ALFREDJustin Dannemiller*, Haoyang He*, Conner Pulling*, Eduardo Trevino*, and Renos Zabounidis*May 2024Embodied Instruction Following (EIF) tasks focus on agents that navigate and interact with environments based on natural language instructions. Unlike other embodied intelligence tasks, EIF requires agents to adapt to unseen environments and interact dynamically, creating significant challenges. This paper explores the performance of EIF methods Prompter and FILM with updated foundational models for computer vision and natural language processing. Using the ALFRED dataset, a simulated environment for vision-and-language navigation, we evaluate the impact of integrating DepthAnything and MaskDINO. Our findings indicate that ground-truth depth and instance segmentation significantly boost performance, with DepthAnything outperforming Prompters depth estimator by 40% (improvement in average MSE) without fine-tuning, and MaskDino achieving competitive but slightly lower results compared to Prompter’s existing MaskRcnn. These results demonstrate the potential of updated models to improve embodied agents’ adaptability and effectiveness in complex tasks. With further finetuning, these methods could significantly surpass their predecessors.
-
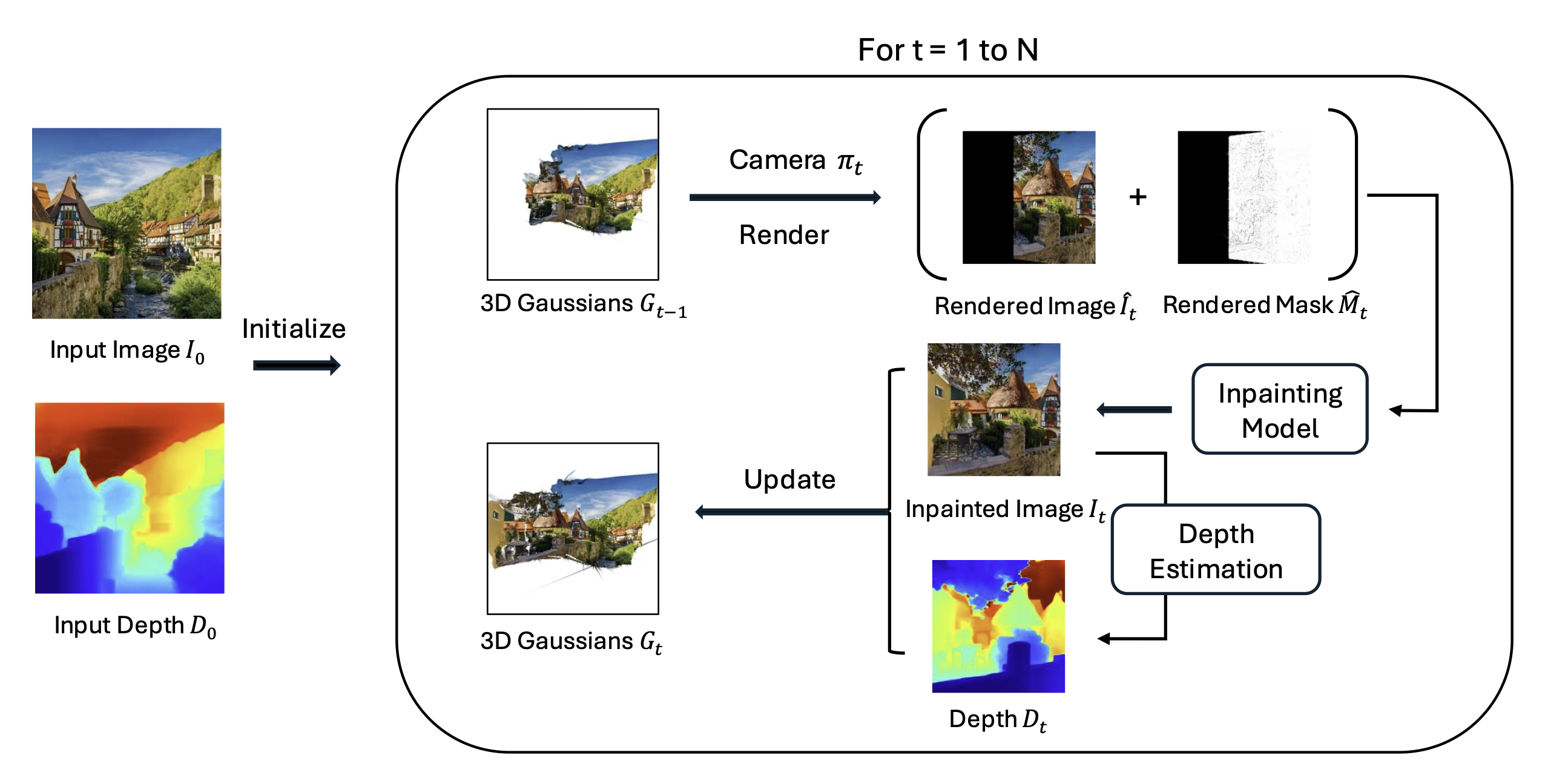 SceneGaussian: Unconstrained Generation of 3D Gaussian Splatting ScenesHanzhe Hu, Qin Han, and Haoyang HeMay 2024
SceneGaussian: Unconstrained Generation of 3D Gaussian Splatting ScenesHanzhe Hu, Qin Han, and Haoyang HeMay 2024In this paper, we introduced SceneGaussian, an innovative framework for generating consistent 3D scenes from a single image input along an arbitrary camera trajectory using 3D Gaussian splatting. Our method efficiently leverages off-the-shelf models for depth estimation and image inpainting to dynamically update and maintain a realistic 3D scene. Our experiments demonstrate that SceneGaussian not only produces visually appealing and realistic scenes but also performs competitively with existing methods in terms of qualitative assessments using CLIPScore metrics.
-
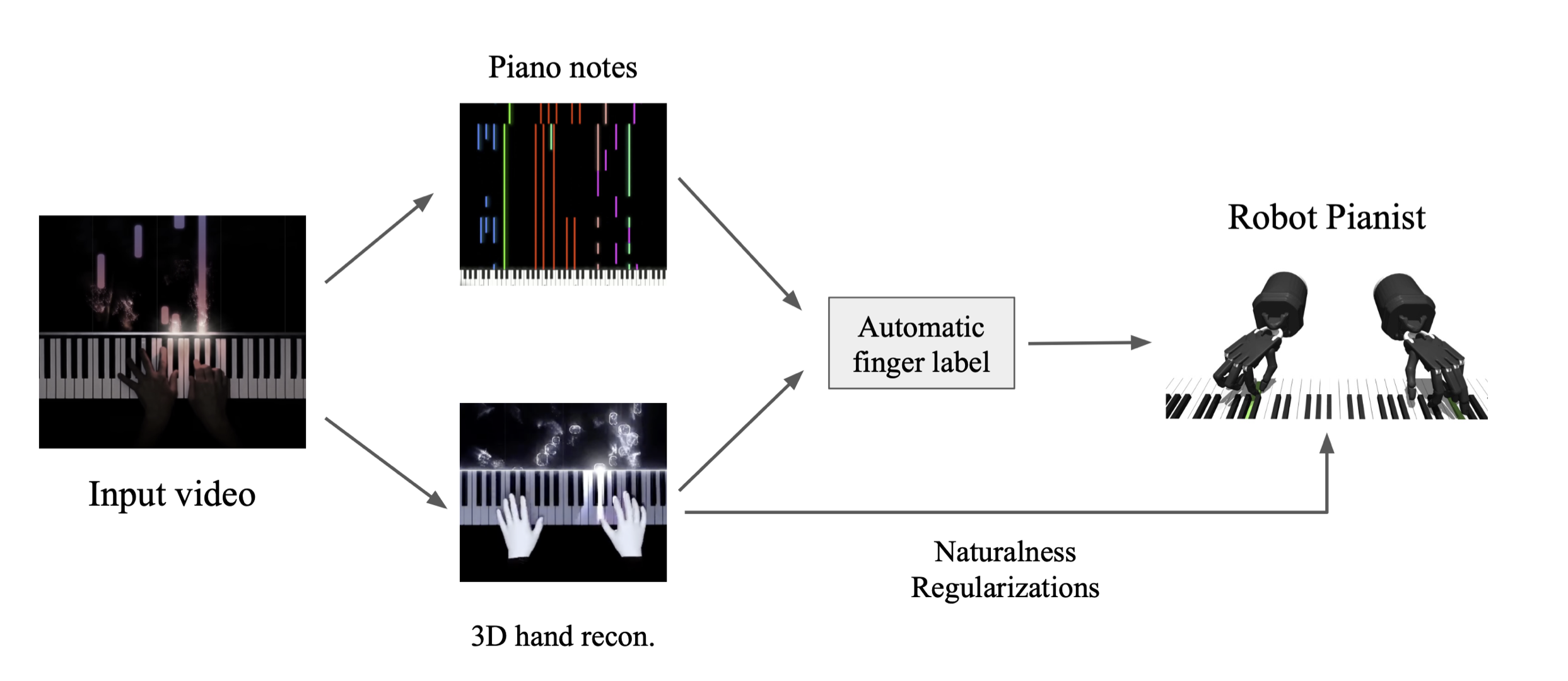 Natural Dexterous Piano Playing at Scale With Video Hand PriorsJeff Tan, Yuanhao Wang, and Haoyang HeMay 2024
Natural Dexterous Piano Playing at Scale With Video Hand PriorsJeff Tan, Yuanhao Wang, and Haoyang HeMay 2024Building robotic hands with human-like dexterity is one of the most important open problems in robotics. Despite tremendous research, recent methods are limited to a narrow set of dexterous tasks such as object grasping and in-hand cube manipulation. Although more challenging tasks such as robotic piano playing have been recently demonstrated, existing RL approaches are unable to play arbitrary pieces zero-shot, and are limited to playing a specific 30-second piece given dense expert fingering labels as input. To improve the scalability of this system and avoid the need for expert labeling, we introduce a method to learn piano playing directly from widely-available YouTube videos, by generating automated fingering labels with state-of-the-art hand pose estimation and music note transcription. Our method is able to learn a challenging 14-minute long piano piece by copying the fingering from human videos, enabling large-scale training data generation for zero-shot piano playing at scale.
2023
-
 A Survey on Offline Model-Based Reinforcement LearningHaoyang HeMay 2023
A Survey on Offline Model-Based Reinforcement LearningHaoyang HeMay 2023Model-based approaches are becoming increasingly popular in the field of offline reinforcement learning, with high potential in real-world applications due to the model’s capability of thoroughly utilizing the large historical datasets available with supervised learning techniques. This paper presents a literature review of recent work in offline model-based reinforcement learning, a field that utilizes model-based approaches in offline reinforcement learning. The survey provides a brief overview of the concepts and recent developments in both offline reinforcement learning and model-based reinforcement learning, and discuss the intersection of the two fields. We then presents key relevant papers in the field of offline model-based reinforcement learning and discuss their methods, particularly their approaches in solving the issue of distributional shift, the main problem faced by all current offline model-based reinforcement learning methods. We further discuss key challenges faced by the field, and suggest possible directions for future work.
2022
-
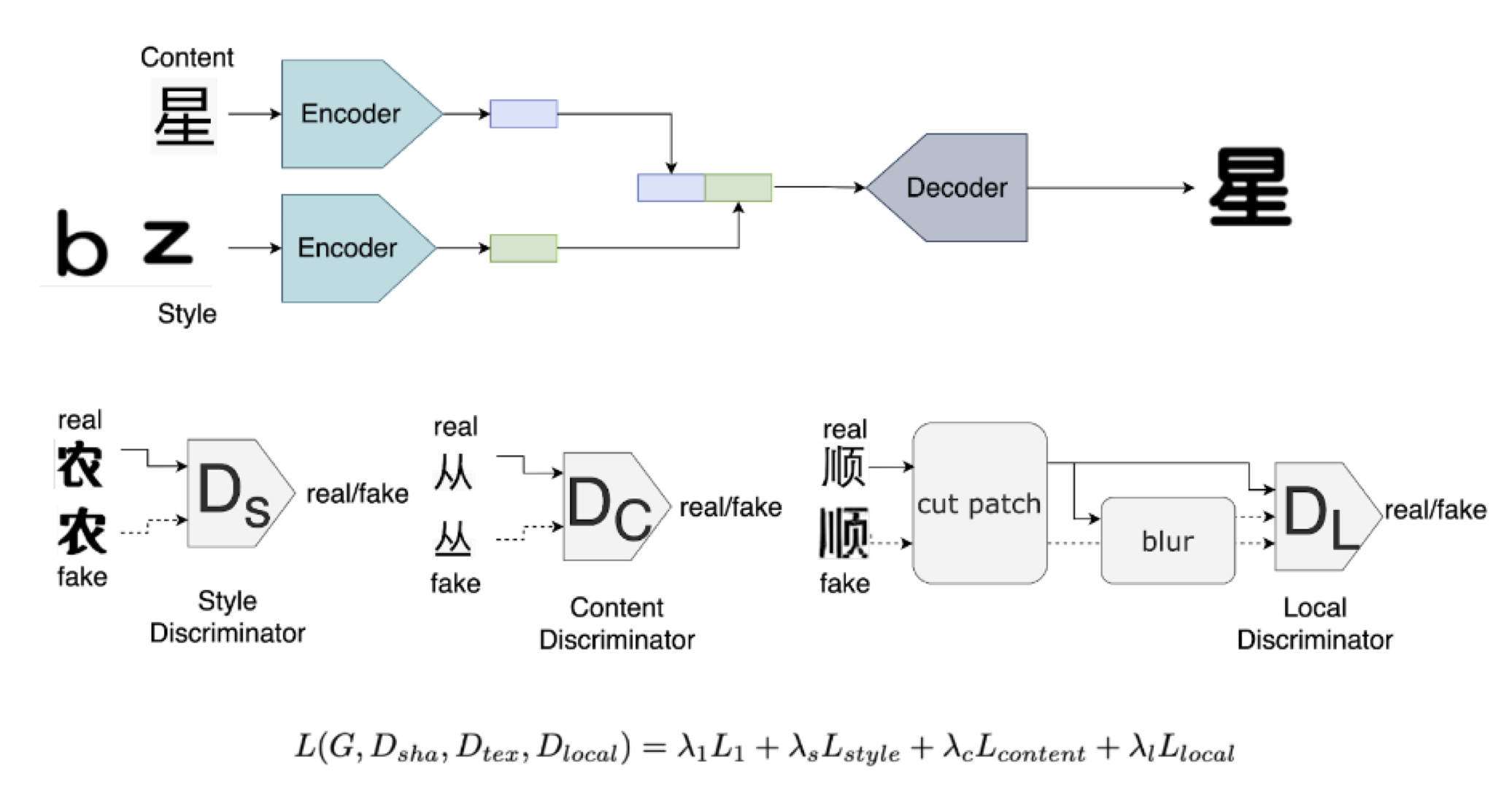 GAS-NeXt: Few-Shot Cross-Lingual Font GeneratorHaoyang He*, Xin Jin*, and Angela Chen*Dec 2022
GAS-NeXt: Few-Shot Cross-Lingual Font GeneratorHaoyang He*, Xin Jin*, and Angela Chen*Dec 2022Generating new fonts is a time-consuming and labor-intensive task, especially in a language with a huge amount of characters like Chinese. Various deep learn- ing models have demonstrated the ability to efficiently generate new fonts with a few reference characters of that style, but few models support cross-lingual font generation. This paper presents GAS-NeXt, a novel few-shot cross-lingual font generator based on AGIS-Net and Font Translator GAN, and improve the performance metrics such as Fréchet Inception Distance (FID), Structural Similarity Index Measure (SSIM), and Pixel-level Accuracy (pix-acc). Our approaches include replacing the original encoder and decoder with the idea of layer attention and context-aware attention from Font Translator GAN, while utilizing the shape, texture, and local discriminators of AGIS-Net. In our experiment on English-to- Chinese font translation, we observed better results in fonts with distinct local features than conventional Chinese fonts compared to results obtained from Font Translator GAN. We also validate our method on multiple languages and datasets.
-
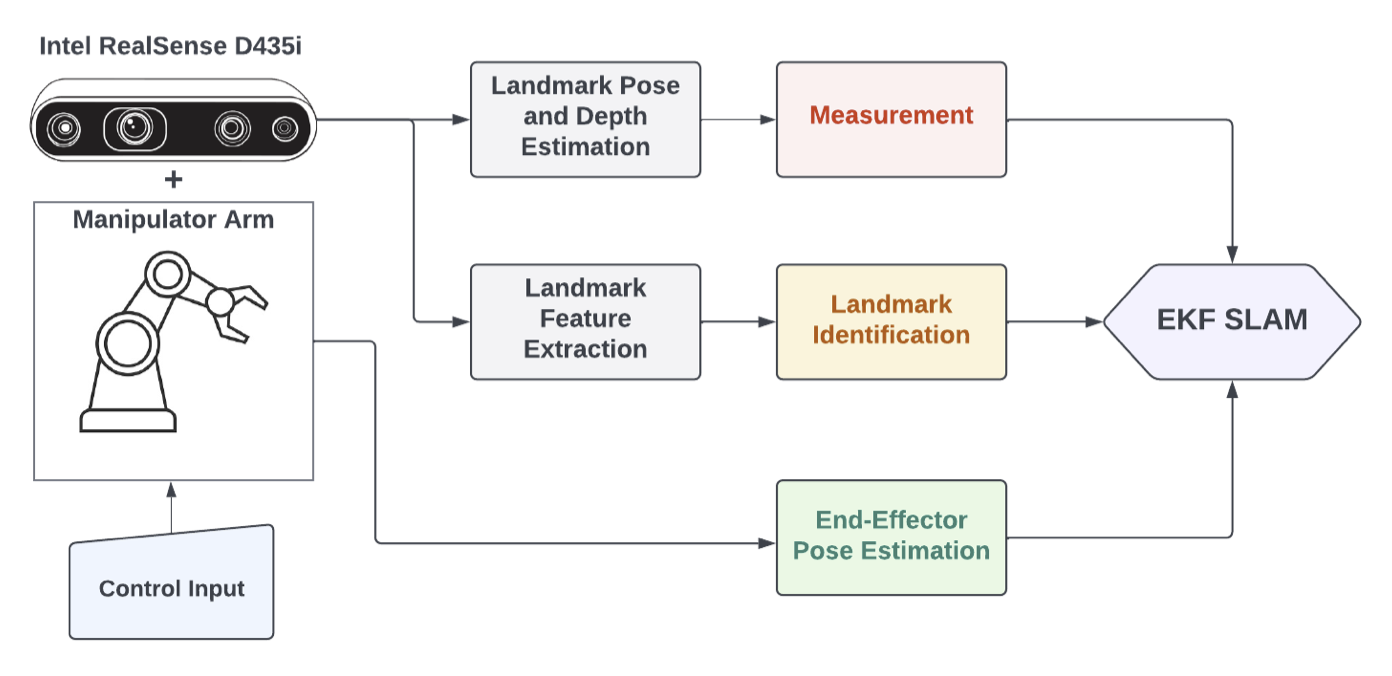 Automatic Eye-in-Hand Calibration using EKFAditya Ramakrishnan*, Chinmay Garg*, Haoyang He*, Shravan Kumar Gulvadi*, and Sandeep KeshavegowdaNov 2022
Automatic Eye-in-Hand Calibration using EKFAditya Ramakrishnan*, Chinmay Garg*, Haoyang He*, Shravan Kumar Gulvadi*, and Sandeep KeshavegowdaNov 2022In this paper, a self-calibration approach for eye-in- hand robots using SLAM is considered. The goal is to calibrate the positioning of a robotic arm, with a camera mounted on the end-effector automatically using a SLAM-based method like Extended Kalman Filter (EKF). Given the camera intrinsic parameters and a set of feature markers in a work-space, the camera extrinsic parameters are approximated. An EKF based measurement model is deployed to effectively localize the camera and compute the camera to end-effector transformation. The proposed approach is tested on a UR5 manipulator with a depth-camera mounted on the end-effector to validate our results.